# SQL
# Flag
- http://www.h2database.com (opens new window)
- http://hsqldb.org (opens new window)
- https://github.com/FirebirdSQL/firebird (opens new window)
- https://db-engines.com/en/ranking (opens new window)
- 分布式 https://github.com/cockroachdb/cockroach (opens new window)
- https://github.com/influxdata/influxdb (opens new window)
# MySQL
MySQL优化工具
- https://github.com/major/MySQLTuner-perl (opens new window)
- https://github.com/BMDan/tuning-primer.sh (opens new window)
- pt-query-digest、pt-variable-advisor:https://www.percona.com/downloads/percona-toolkit/LATEST/ (opens new window)
- https://www.red-gate.com/products (opens new window)
- https://www.sqlgate.com (opens new window)
- https://www.jetprofiler.com (opens new window)
- https://www.solarwinds.com/zh/database-performance-monitoring-software (opens new window)
MySql 5.0 以上字符串数据类型可以存的汉字个数
注意谨慎选择较大的存储数据类型
- UTF8MB4编码:一个汉字 = 4 个字节,英文是一个字节(bytes)
- UTF8编码:一个汉字 = 3 个字节,英文是一个字节(bytes)
- GBK编码: 一个汉字 = 2 个字节,英文是一个字节(bytes)
- 在UTF8状态下 longtext : 4294967295/3=1431655765 个汉字,约14亿,存储空间占用:4294967295/1024/1024/1024=4G 的数据
- 在UTF8状态下 mediumtext : 16777215/3=5592405 个汉字,约560万,存储空间占用:16777215/1024/1024=16M 的数据
- 在UTF8状态下 text : 65535/3=21845个汉字,约20000,存储空间占用:65535/1024=64K 的数据
- 在UTF8状态下 tinytext : 256/3=85个汉字,存储空间占用:256 bytes
- 在UTF8MB4状态下 varchar : (65535 - 2) / 4 = 16383 个汉字,英文也为 16383 个字符串,存储空间占用:64k
- 在UTF8状态下 varchar : (65535 - 2) / 3 = 21844 个汉字,英文也为 21844 个字符串,存储空间占用:64k
- 在GBK状态下 varchar : (65535 - 2) / 2 = 32766 个汉字,英文也为 32766 个字符串,存储空间占用:64k
varchar 超过255个字节会有2字节的额外占用空间开销,所以减2,如果是255以下,则减1
通过分组聚合GROUP_CONCAT实现分析函数(开窗函数)
SELECT
product_id,
branch,
GROUP_CONCAT(t.stock ORDER BY t.stock DESC ) stocks
FROM (SELECT *
FROM product_stock) t
GROUP BY product_id,branch
# 索引
索引是加速搜索引擎检索数据的一种特殊表查询。简单地说,索引是一个指向表中数据的指针。 索引也是一张表,该表保存了主键与索引字段,并指向实体表的记录。因为更新表时,MySQL不仅要保存数据,还要保存一下索引文件。 建立索引会占用磁盘空间的索引文件。
一个数据库中的索引与一本书的索引目录是非常相似的。 拿汉语字典的目录页(索引)打比方,我们可以按拼音、笔画、偏旁部首等排序的目录(索引)快速查找到需要的字。
索引有助于加快 SELECT 查询和 WHERE 子句,但它会减慢使用 UPDATE 和 INSERT 语句时的数据输入。索引可以创建或删除,但不会影响数据。 使用 CREATE INDEX 语句创建索引,它允许命名索引,指定表及要索引的一列或多列,并指示索引是升序排列还是降序排列。 索引也可以是唯一的,与 UNIQUE 约束类似,在列上或列组合上防止重复条目。
- 在线DDL操作 - 官网 (opens new window)
- MySQL 全文索引实现简单版搜索引擎 (opens new window)
- mysql数据库的索引类型 (opens new window)
- 详细介绍mysql索引类型:FULLTEXT、NORMAL、SPATIAL、UNIQUE (opens new window)
- MYSQL8.0全文索引使用 (opens new window)
-- 强制使用指定索引
FORCE INDEX (索引名)
从数据结构角度
- BTREE
- HASH
从物理存储角度
- 聚集索引(clustered index)
- 非聚集索引(non-clustered index)
从逻辑角度
- Normal(普通索引)
CREATE INDEX 索引名 ON 表名(`字段名`(length));
ALTER TABLE 表名 ADD INDEX IndexName(`字段名`(length));
- Unique(唯一索引)
CREATE UNIQUE INDEX 索引名 ON 表名(`字段名`(length));
ALTER TABLE 表名 ADD UNIQUE (column_list);
- 组合索引
CREATE INDEX 索引名 On 表名(`字段名`(length),`字段名`(length),...);
ALTER TABLE 表名 ADD INDEX 索引名 (id,name);
SPATIAL(空间索引)
Full Text(全文索引)
- https://dev.mysql.com/doc/refman/8.0/en/fulltext-search.html (opens new window)
- ngram全文分析器 - 官网 (opens new window)
# 最小字符长度,默认是4,必须要匹配大于4的才会有返回结果
ft_min_word_len=2
# 存储在InnoDB的FULLTEXT索引中的最小词长
innodb_ft_min_token_size=2
# 中文检索分词插件,设置分词大小,取值范围是1到10,默认值是2,分词的SIZE越大,索引的体积就越大
# 注意位置必须放在全文索引的配置后面
ngram_token_size=1
-- 查看所有全文索引相关参数
SHOW GLOBAL VARIABLES LIKE '%ft%';
SHOW GLOBAL VARIABLES LIKE 'ngram_token_size';
ALTER TABLE tablename ADD FULLTEXT(column1, column2);
--
SELECT * FROM 表名 WHERE MATCH(column1, column2) AGAINST('aa','bb','cc'...);
-- 使用IN BOOLEAN MODE匹配不完整单词,默认IN NATURAL LANGUAGE MODE(自然语言模式)
SELECT * FROM 表名 WHERE MATCH(字段) AGAINST('关键词' IN BOOLEAN MODE);
重新构建索引文件
-- 对于InnoDB存储引擎的表无效
REPAIR TABLE 表名 QUICK;
-- InnoDB对表进行索引的重新构建
ALTER TABLE 表名 ENGINE=INNODB;
-- 使用优化指令也可以起到同样的作用,同时这个指令会完成更多的优化作用。OPTIMIZE TABLE运行过程中,MySQL会锁定表
OPTIMIZE TABLE 表名;
-- 执行之后会返回如下信息,但实际上是执行成功的
-- Table does not support optimize, doing recreate + analyze instead
# ORACLE
系统表
USER_TABLES当前用户拥有的表:TABLE_NAME,TABLESPACE_NAME,LAST_ANALYZEDDBA_TABLES包括系统表:多了OWER列ALL_TABLES所有用户的表:多了OWER列ALL_OBJECTS当前用户有访问权限的所有对象:OWER,OBJECT_NAME,SUBOBJECT_NAME,OBJECT_ID,CREATED,LAST_DDL_TIME,TIMESTAMP,STATUSUSER_TAB_COLUMNS当前用户拥有的表字段ALL_TAB_COLUMNSDBA_TAB_COLUMNSUSER_TAB_COMMENTS当前用户拥有的表注释 :TABLE_NAME,TABLE_TYPE,COMMENTSDBA_TAB_COMMENTS:多了OWER列ALL_TAB_COMMENTS:多了OWER列USER_COL_COMMENTS当前用户拥有的表字段注释 :TABLE_NAME,COLUMN_NAME,COMMENTSDBA_COL_COMMENTS:多了OWER列ALL_COL_COMMENTS:多了OWER列
SELECT * FROM USER_TAB_COMMENTS WHERE COMMENTS LIKE '%摘要%'
分组获取最新一条数据(查询各组最新的一条记录)
- over partition by 分析函数(开窗函数)
SELECT * FROM (
SELECT ROW_NUMBER() OVER(PARTITION BY 分组字段名 ORDER BY 排序字段名 DESC) rn,t.* FROM test1 t
) WHERE rn = 1;
SELECT * FROM (
select eb_vipcode,eb_time,MAX(eb_time) over(partition by eb_vipcode) as "atime" from eb_daskexpdateinfo
) x where eb_time = "atime";
SELECT * FROM (
select ID_,COMPANY_NAME,USAGE_RATE,CREATE_TIME
,MAX(CREATE_TIME) over(partition by COMPANY_NAME) as "atime" from SPEC_RATE_ORIGIN
) x where CREATE_TIME = "atime";
- group by
SELECT eb_vipcode,MAX(eb_time) AS "atime" FROM eb_daskexpdateinfo group by eb_vipcode
- inner join
SELECT A.* FROM SPEC_RATE_ORIGIN A INNER JOIN (
SELECT COMPANY_NAME,MAX(CREATE_TIME) AS "atime" FROM SPEC_RATE_ORIGIN group by COMPANY_NAME
) B ON A.COMPANY_NAME = B.COMPANY_NAME AND A.CREATE_TIME = B."atime";
一次插入多条数据
INSERT ALL
INTO a表(字段) VALUES(各个值1)
INTO a表(字段) VALUES(其它值2)
INTO a表(字段) VALUES(其它值3)
SELECT 1 FROM DUAL;
插入或更新 upsert
MERGE INTO table_name alias1
USING (table|view|sub_query) alias2
ON (join condition)
WHEN MATCHED THEN
UPDATE table_name SET col1 = col_val1
WHEN NOT MATCHED THEN
INSERT (column_list) VALUES (column_values);
# Postgre
- https://github.com/topics/postgrest (opens new window)
- https://github.com/topics/postgresql (opens new window)
- https://github.com/dhamaniasad/awesome-postgres (opens new window)
- https://github.com/citusdata (opens new window)
- https://github.com/postgres/postgres (opens new window)
- https://github.com/PostgREST/postgrest (opens new window)
- 文本搜索和分析 https://github.com/zombodb/zombodb (opens new window)
- https://github.com/supabase/supabase (opens new window)
-- 插入或更新 upsert
INSERT INTO table_name(column_list)
VALUES(value_list)
ON CONFLICT target action;
# SQLite3
- SQLite教程(内置日期和时间函数) (opens new window)
- SQLite 教程 (opens new window)
- SQLite 教程 (opens new window)
- SQLite3 数据类型与亲和类型 (opens new window)
- https://github.com/utelle/wxsqlite3 (opens new window)
- 分布式关系数据库 https://github.com/rqlite/rqlite (opens new window)
连接符
| 连接符 | 说明 |
|---|---|
| - | 算术减法 |
| != | 关系不等于 |
| % | 算术模量 |
| & | 逻辑与 |
| * | 算术乘法 |
| / | 算术除法 |
| | | 逻辑或 |
| || | 字符串串联 |
| + | 算术加法 |
| < | 关系小于 |
| << | 按位右移 |
| <= | 关系式小于或等于 |
| <> | 关系不等于 |
| = | 关系等于 |
| == | 关系等于 |
| > | 关系大于 |
| >= | 关系大于或等于 |
| >> | 按位左移 |
| AND | 逻辑与 |
| GLOB | 关系文件名匹配 |
| IN | 逻辑输入 |
| LIKE | 关系字符串匹配 |
| OR | 逻辑或 |
# Redis
- https://redis.io/documentation (opens new window)
- https://github.com/huangz1990/redis-3.0-annotated (opens new window)
- https://github.com/huangz1990/redis (opens new window)
- https://github.com/antirez/redis-doc (opens new window)
- https://github.com/guodongxiaren/redis-wiki (opens new window)
- redis常用特性:https://github.com/LxyTe/redis (opens new window)
- JuiceFS是基于Redis和S3构建的分布式POSIX文件系统 https://github.com/juicedata/juicefs (opens new window)
# Memcached
# MongoDB
# 免费数据库
MySQL
SQLServer
PostgresqlSQL
Redis
# 标准SQL
在标准 SQL 中,字符串使用的是单引号。
如果字符串本身也包括单引号,则使用两个单引号(注意,不是双引号,字符串中的双引号不需要另外转义)。
有些SQL中使用双引号字符串,是其它的数据库对 SQL 的扩展,比如在MySQL中允许使用单引号和双引号两种。
保留字不能用于表名,比如desc,此时需要加入反引号来区别,但使用表名时可忽略反引号。
保留字不能用于字段名,比如desc,此时也需要加入反引号,并且insert等使用时也要加上反引号
# SQL1992
sql分类
- 笛卡尔积 (表乘表)
- 等值连接 表的连接条件使用
= - 非等值连接 表的连接条件使用
>、>=、 <、<=、!=、any等 - 自连接 自己连接自己
- 外连接
- 左外连接,
+在等号右边 - 右外连接,
+在等号左边 +在哪一边的列,该表就补充null
# SQL1999
sql分类
- cross join 交叉连接 (笛卡尔积) ,不需要on关键字
- natural join 自然连接 (找两个表中相同的列,进行等值匹配),不需要on关键字
- inner join 内连接
- 必须有on关键字,on表示连接条件
- inner关键字可以省略
- outer join 外连接,outer关键字可以省略
- left outer join
- right outer join
- full outer join
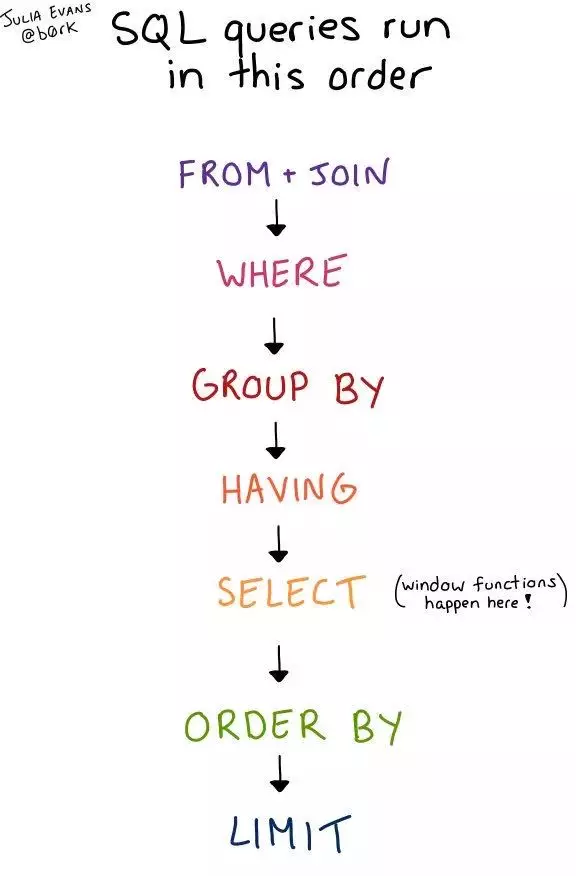
sql99语法:通过join关键字实现连接
- 含义:1999年推出的sql语法
- 支持: 等值连接、非等值连接 (内连接)、外连接
select 字段,...
from 表1
【inner|left outer|right outer】join 表2 on 连接条件
【inner|left outer|right outer】join 表3 on 连接条件
【where 分组前筛选条件】
【group by 分组字段】
【having 分组后的筛选条件】
【order by 最后执行的,排序的字段或表达式】
好处:语句上,连接条件和筛选条件实现了分离,简洁明了!
# 自连接
- cross join:自然连接。主要用于产生笛卡尔积。
select * from emp cross join dept;
- natural join:自然连接。这种情况下,数据库会自动找到一个字段来消除笛卡尔积。一般来说,数据库会找那些通过外键约束关联的字段。因此,有较大的局限性。
select * from emp natural join dept;
案例:查询员工名和直接上级的名称
- sql99
SELECT e.last_name,m.last_name
FROM employees e
JOIN employees m ON e.`manager_id`=m.`employee_id`;
- sql92
SELECT e.last_name,m.last_name
FROM employees e,employees m
WHERE e.`manager_id`=m.`employee_id`;
# 子查询
含义:一条查询语句中又嵌套了另一条完整的select语句,其中被嵌套的select语句,称为子查询或内查询在外面的查询语句,称为主查询或外查询
特点:
- 子查询都放在小括号内
- 子查询可以放在from后面、select后面、where后面、having后面,但一般放在条件的右侧
- 子查询优先于主查询执行,主查询使用了子查询的执行结果
- 子查询根据查询结果的行数不同分为以下两类:
- 单行子查询,结果集只有一行,一般搭配单行操作符使用:
> < = <> >= <=,非法使用子查询的情况:- 子查询的结果为一组值
- 子查询的结果为空
- 多行子查询,结果集有多行,一般搭配多行操作符使用:any、all、in、not in
- in: 属于子查询结果中的任意一个就行
- any和all往往可以用其他查询代替
- 单行子查询,结果集只有一行,一般搭配单行操作符使用:
# 分页查询
应用场景:实际的web项目中需要根据用户的需求提交对应的分页查询的sql语句
select 字段|表达式,...
from 表
【where 筛选条件】
【group by 分组字段】
【having 分组后的筛选条件】
【order by 排序的字段】
limit 【起始的记录索引,】 每页的记录数;
特点:
- 起始条目索引从0开始
- limit子句放在查询语句的最后
- 公式:
select * from 表 limit (page-1)*sizePerPage, sizePerPage- 假如:每页显示条目数sizePerPage,要显示的页数 page
Oracle分页
select * from (
select rownum as rn, first_name from (select first_name from some_table order by first_name)
) where rn > 100 and rn <= 200
select * from (select ncallernm, count(*) tol from tmp_86 group by ncallernm order by tol desc) where rownum<20
select * from OB_CALL_DATA_LOG rownum<101 minus select * from OB_CALL_DATA_LOG rownum>9
# 连接查询
- 连接查询的分类:
- 按年代分为sql192标准仅仅支持内连接,sql199标准支持内连接,左外连接,右外连接,交叉连接 - 按功能分为内连接,外连接,交叉连接
sql92标准:内连接包括
- 等值连接:
select name,boyname form boys,beauty where beauty.boyfriend_id = boys.id;- 多表等值连接的结果为多表的交集部分;n表连接至少需要n-1个连接条件;多表的顺序没有要求;一般需要为表起别名
- 非等值连接:
select salary,grade_level form employees e,job_grades g where salary between g.'lowest_sal' and 'highest_sal'; - 自连接:
select e.employee_id,e.last_name,m.employee_id,m.last_name from employees e,employees m where e.'manager_id' = m.'employee_id';
sql99语法:包括内连接(inner),外连接(left outer ,right outer,full outer),交叉连接(cross join)
语法:
select 查询列表 form 表1 别名 【连接类型】 join 表2 别名 on 连接条件 【where 筛选条件】
特点:添加排序,分组,筛选,inner可以省略,筛选条件放在where后面,连接条件放在on后面,提高分离性
内连接:
select 查询列表 form 表1 别名 inner join 表2 别名 on 连接条件- 等值连接:
select last_name,department_name form employee e inner join department d on e.'department_id' = d.'department_id'; - 非等值连接:
select salary,grade_level from employee e join job_grades g on e.'salary' between g.'lowest_sal' and g.'highest_sal' group by grade_level; - 自连接:
select e.last_name,m.last_name from employees e join employees m on e.'manager_id' = m.'employee_id' where e.'last_name' like '%k%';
- 等值连接:
外连接:用于查询一个表中有,一个表中没有的,外连接的查询结果是主表中的所有记录 如果从表中有和它匹配的值,则显示出来,没有显示null
- 左外连接,left join左边的是主表:
select b.name,bo.* form beauty b left outer join boys bo on b.'boyfriend_id' = bo.'id'; - 右外连接,right join右边的是主表:
select b.name,bo.* form boys bo right outer join beauty b on b.'boyfriend_id' = bo.'id'; - 全外连接,等于内连接的结果,加上表1有但表2没有的,加上表2有表一没有的 use girls;
select b.*,bo.* from beauty b full outer join boys bo on b.'boyfriend_id' = 'bo.id'; - 交叉连接:
select b.*,bo.* form beauty b cross join boys bo;
- 左外连接,left join左边的是主表:
# CASE
同其他编程语言中的
switch...case或if...else语句,可以直接在order by后面使用自定义排序
Case函数在满足了某个符合条件后,剩下的条件将会被自动忽略,因此,即使满足多个条件,执行过程中也只认第一个条件。 在使用 CASE WHEN时,可以把它当作一个没有字段名的字段,字段值根据条件确认,在需要使用字段名时可以是用
as来定义别名。
- 简单Case函数
简单Case函数胜在简洁,但是它只适用于这种单字段的单值比较
CASE sex
WHEN '0' THEN '男'
WHEN '1' THEN '男'
WHEN '2' THEN '女'
ELSE '其他' END
- Case搜索函数
Case搜索函数的优点在于适用于所有比较的情况
CASE WHEN sex = '1' and sex = '0' THEN '男'
WHEN sex = '2' THEN '女'
ELSE '其他' END
# SQL2003
开窗函数简介:与聚合函数一样,开窗函数也是对行集组进行聚合计算,但是它不像普通聚合函数那样每组只返回一个值 ,开窗函数可以为每组返回多个值,因为开窗函数所执行聚合计算的行集组是窗口
← MySQL笔记 mysql-udf安装 →